Concepts
ARK
What is ARK?
The Archival Resource Key (ARK) is an open PID system that provides reliable references for information objects. According to Kunze and Bermès (2008) in their work "The ARK Identifier Scheme," Archival Resource Keys (ARKs) are a flexible and low-cost alternative for assigning persistent identifiers. Any organization has the possibility to create an unlimited number of identifiers using a flexible metadata scheme. However, most ARK implementations rely on internal solutions that are isolated from each other, leading to issues such as PID duplication, cost inefficiency, and low fault tolerance.
To be used in various applications mentioned above, the ARK was conceived to be generic. Furthermore, the fundamental design of ARK are:
These designs were incorporated in ARK and distributed in two main components; the ARK identifiers and the ARK system architecture. The core concept of the ARK identifier is that the identifier attribution process was created considering a self-sufficient away. The ARK does not need a central authority to generate a new identifier, mainly because the ARK does not need external information to assign a new unique identifier. To enable self-sufficient identifiers, the ARK incorporates Name Assigning Authority Numbers (NAANs) identification in the object identifier. An organization (e.g., an university) must be registered within the ARK Alliance to generate an ARK identifier. In this registration process, the organization will receive a NAAN identification, e.g., the Instituto Brasileiro de Informação em Ciência e Tecnologia (IBICT) has the NAAN 80033. The NAAN is used as the prefix of the ARK identifier, making it impossible for any other organization to generate IDs with this prefix. A typical ARK identifier comprises four parts, NAAM, shoulder, blade, and tip. Figure 1 represents hypothetical ARK identifier
The ark:/, designates the schema of the identifiers. The 80033 is the NAAM responsible for the identifier. The shoulder (in Figure 1 the shoulder is tqbmb3) designates the organization unit (e.g., university department) responsible for the identifier, defining sub-namespace. Unique shoulders guarantee that names within the sub-namespace will also be unique outside of it, and the unit need only focus on creating the rest of the key in a unique way. The blade (kh97gh8) is a unique id generated by the unit. Finally, the tip (w) is the verification digit of all parts of the ARK identifier.
Typical ARK
A typical ARK identifier comprises four parts, NAAM, shoulder, blade, and tip. Figure 1 represents hypothetical ARK identifier.
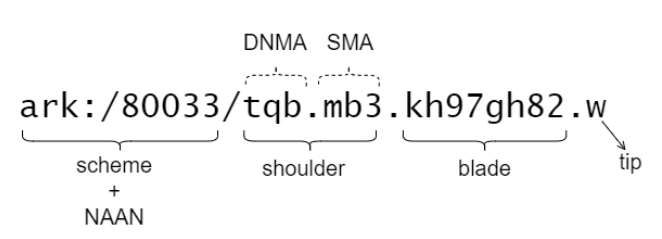
Figure 1- ARK identifier
dARK
What is dARK?
The decentralized ARK identifier assignment system, which we call dARK, employs an approach that allows multiple institutions to collaboratively manage their persistent ARK identifier system using a common decentralized infrastructure based on nodes of a blockchain consortium network. In this way, the data is not owned, stored, or controlled by a single organization, but by all participants in the network. Considering that dARK users will participate in a well-organized blockchain consortium network, the PID data will be replicated securely, reliably, audibly, and accessibly across all nodes of this network. Even if an institution disappears, the stored data will persist in the remaining nodes of the network. Furthermore, given the blockchain consortium network, the cost of storing and managing the PID data will be low. It is estimated that each dARK identifier assignment will require 12KB of disk storage. Additionally, a standard server instance has been designed to run the decentralized application (for example, in the experimental environment, a virtual machine with 4 Xeon cores, 16GB of RAM, and 30GB of storage was used).
dARK Identifiers
To enable the decentralization of the ARK, first, we have to extend the ARK identifier to be compatible with the new organizational structure of the consortium of institutions that will use the dARK. Thus the proposed extension is fully compatible with ARK identifier assigning rules. This provides an automatic compatibility with standard ARK interoperability protocols. In this structure the ARK Alliance [34] is able to issue just a unique NAAN prefix to an entire blockchain consortium network. For instance, in Brazil, a consortium should be founded by a federal governmental research institute related to science and technology, the Instituto Brasileiro de Informac ̧ ̃ao em Ciência e Tecnologia (IBICT)
In order to decentralize the ARK identifiers, the dARK system was designed with PID management capabilities for the curators of each institution that composes the consortium. To accomplish the aforemen- tioned goal, two new elements were incorporated into the shoulder of the ARK identifier, the Decentralized Name Assigning Authority (DNA) and Section Name Authority (SNA).
The DNA is a shoulder prefix employed to identify which consortium member is responsible for a specific PID assignment. DNA is similar to a NAAN; however, it identifies the institution (authority) responsible within the consortium context. The SNA is used to assign a section authority within an institution. For example, a university could indicate a curator for different libraries by assigning different SNAs for each collection. Figure 1 presents an example of an assigned identifier
Resolver
Information about the resolver.
Get Started
Deploy a Local Node
Instructions on how to deploy a local node.
Integrating with DSPACE
Steps to integrate with DSPACE.
Our Network
Overview
Details about our network and how to connect to it.
List of Nodes
List of nodes in our network.
Topology
Information about the network topology.
Consensus Protocol
Explanation of the consensus protocol used in the network.
Gas Distribution
Details about gas distribution in the network.
Tutorials
Integrating with DSPACE
Steps to integrate with DSPACE.
How to Instantiate a dARK Node
Instructions on how to instantiate a dARK node.
FAQ
Frequently Asked Questions about the software.